VideoMimic is a real-to-sim-to-real pipeline that converts monocular videos into transferable humanoid skills, letting robots learn context-aware behaviors (terrain-traversing, climbing, sitting) in a single policy.
(a) input video
(b) reconstructed environment and human
(c) tracking the motion in sim
We conducted additional experiments to track an internet video of a person crawling down the stairs. This shows our pipeline's ability to learn from scalable web data and its ability to learn diverse motions. (Source of the input video: YouTube)
Stairs climbing up/down: The robot confidently ascends and descends various staircases, showcasing stable and adaptive locomotion.
Sitting/Standing: Our robot demonstrates smooth sitting and standing behaviors on different chairs and benches, adapting to object heights and shapes.
Terrain traversing: Watch the humanoid navigate diverse terrains, including uneven ground, slopes, and stepping over small obstacles.
Input Video
Human + Scene Reconstruction
G1 Retargeted Results
Egoview (RGB/Depth)
Training in Simulation
From a monocular video, we jointly reconstruct metric-scale 4D human trajectories and dense scene geometry. The human motion is retargeted to a humanoid, and with the scene converted to a mesh in the simulator, the motion is used as a reference to train a context-aware whole-body control policy. While our policy does not use RGB conditioning for now, we demonstrate the potential of our reconstruction for ego-view rendering.
Human + World Reconstruction: Our reconstruction pipeline can handle videos with multiple humans and complex environments from Internet. More results in the gallery.
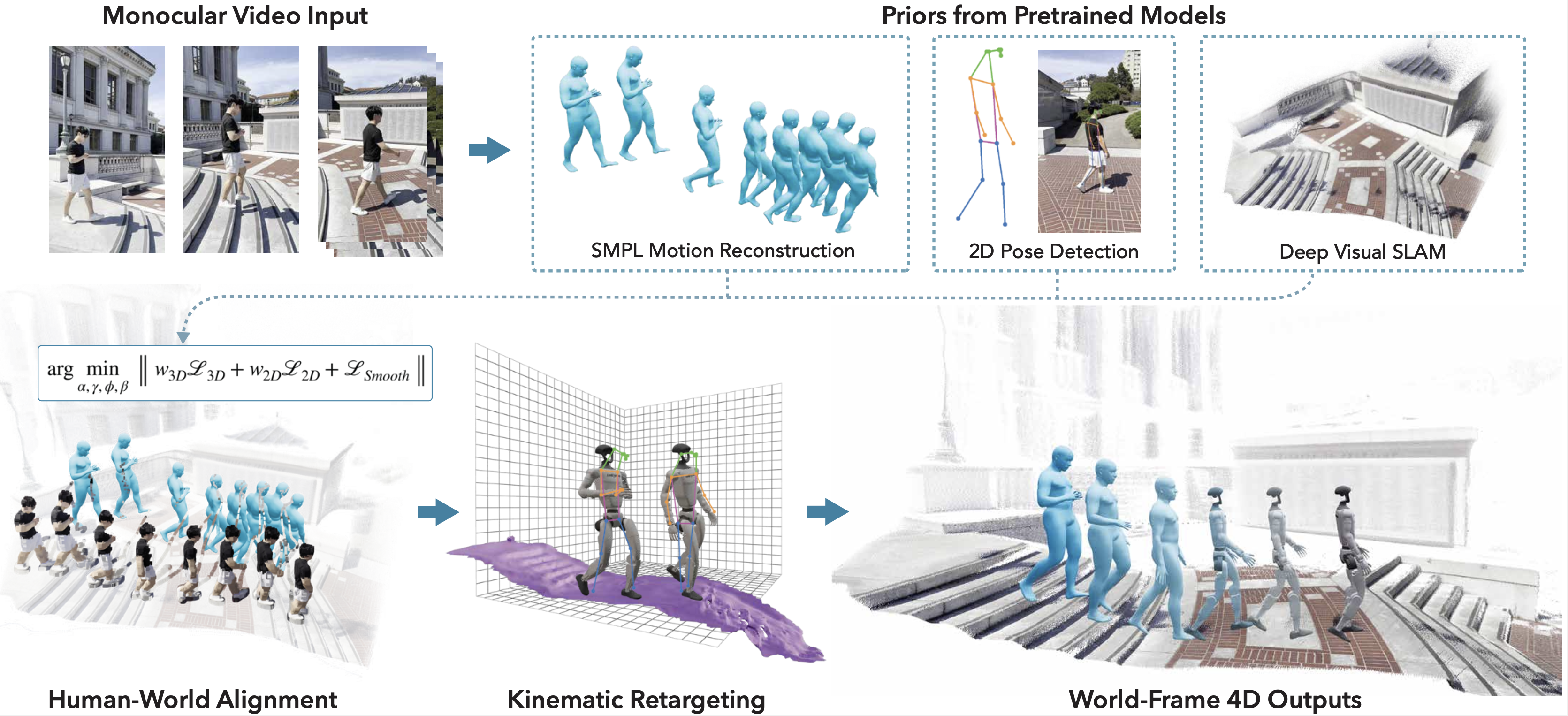
Figure 1: The Real-to-Sim pipeline reconstructs human motion and scene geometry from video, outputting simulator-ready data.
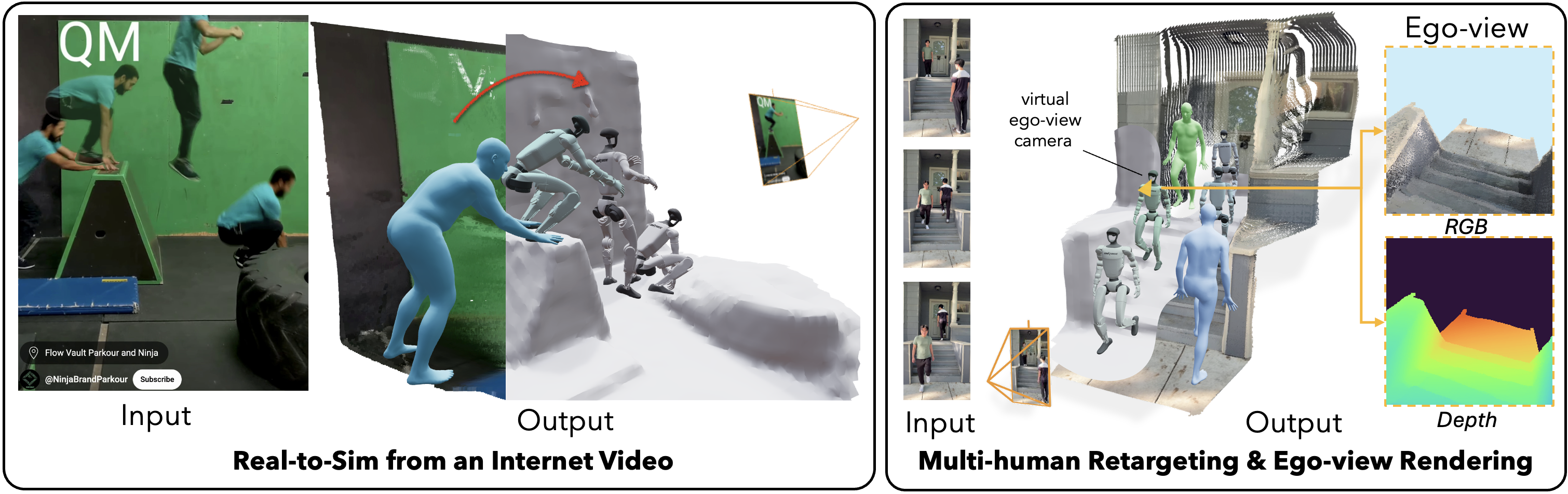
Figure 2: Versatile capabilities include handling internet videos, multi-human reconstruction, and ego-view rendering.
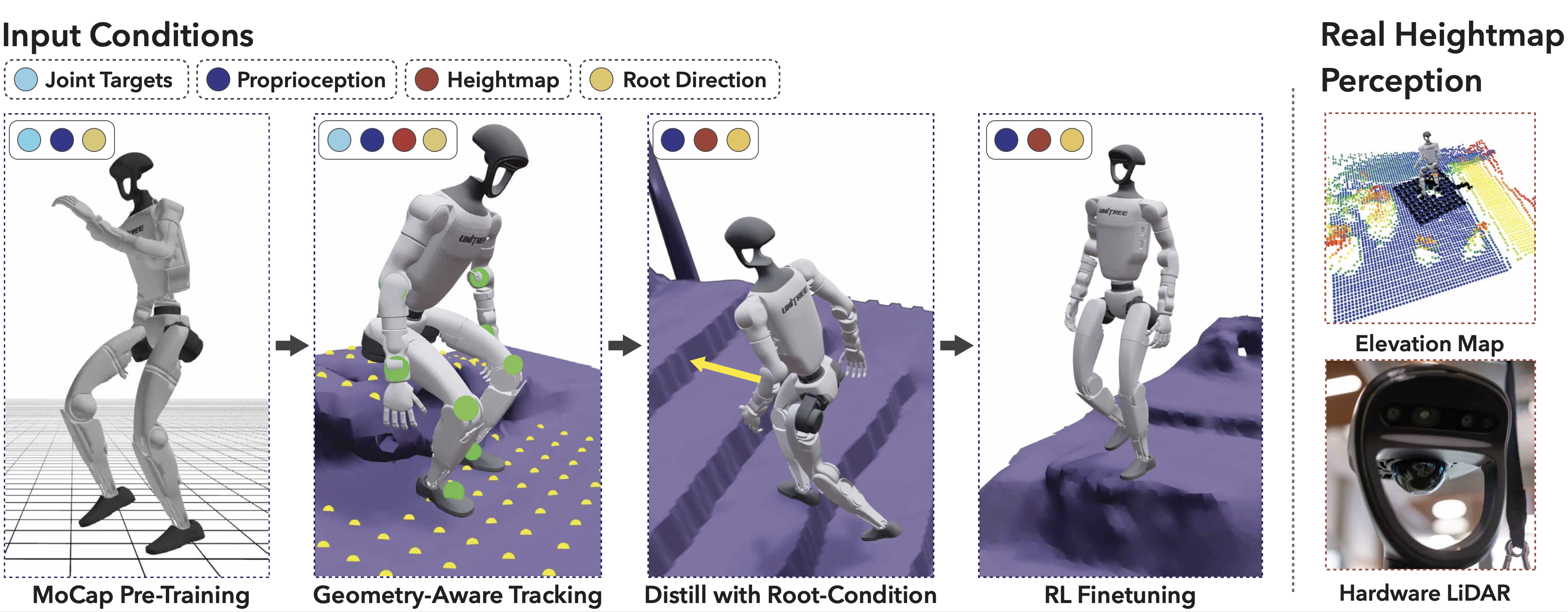
Figure 3: Policy training pipeline in simulation, progressing from MoCap pre-training to environment-aware tracking and distillation.